·大部分大模型“考生”語文、英語科目表現(xiàn)良好,但在數(shù)學(xué)方面還有待加強(qiáng)。閱卷老師點(diǎn)評,在語文科目上,對于語言中的一些“潛臺詞”,大模型尚無法完全理解。在數(shù)學(xué)科目上,大模型的主觀題回答相對凌亂,且過程具有迷惑性。
6月19日,首個大模型高考全卷評測結(jié)果公布。2024年全國高考結(jié)束后,大模型開源開放評測體系——司南評測體系(OpenCompass)選取了6個開源模型包括GPT-4o,針對高考全國新課標(biāo)I卷“語數(shù)外”三門課程展開全卷能力測試。
評測結(jié)果顯示,阿里巴巴開源的Qwen2系列MoE對話模型(Qwen2-72B)、GPT-4o及書生·浦語2.0文曲星(InternLM2-20B-WQX)成為本次大模型高考的前三甲,在語、數(shù)、英三門課程中得分均超過70分。大部分模型“考生”語文、英語科目表現(xiàn)良好,但在數(shù)學(xué)方面還有很大的提升空間。其中,書生·浦語2.0文曲星(InternLM2-20B-WQX)取得了數(shù)學(xué)單科的最高分,超越包括GPT-4o在內(nèi)的所有模型。
司南評測體系OpenCompass是由上海人工智能實(shí)驗室在去年7月的世界人工智能大會上推出,目前升級為OpenCompass2.0,構(gòu)造了一套中英文雙語評測基準(zhǔn),涵蓋語言與理解、常識與邏輯推理、數(shù)學(xué)計算與應(yīng)用、多編程語言代碼能力、智能體、創(chuàng)作與對話等方面。
大模型語言能力表現(xiàn)良好,但數(shù)學(xué)有待提高
司南評測體系團(tuán)隊選取了GPT-4o及在2024年高考前開源的6個模型參與本次“大模型高考”評測。評測采用全國新課標(biāo)I卷,參與評測的所有開源模型,開源時間均早于高考,確保評測 “閉卷”性。同時,成績由具有高考評卷經(jīng)驗的教師人工評判,更加接近真實(shí)閱卷標(biāo)準(zhǔn)。
評測模型包括:法國AI創(chuàng)業(yè)公司Mistral于2024年4月17日開源的對話模型(Mixtral 8x22B)、零一萬物公司于2024年5月12日開源的Yi-1.5系列最大的模型(Yi-1.5-34B)、智譜AI于2024年6月4日推出的最新一代預(yù)訓(xùn)練模型GLM-4系列的開源版本(GLM-4-9B)、上海人工智能實(shí)驗室于2024年6月4日開源的書生·浦語2.0系列文曲星大語言模型(InternLM2-20B-WQX)、阿里巴巴于2024年6月6日開源的Qwen2系列MoE對話模型(Qwen2-57B)、阿里巴巴于2024年6月6日開源的72B稠密模型(Qwen2-72B)。
上述模型的高考“語數(shù)外”三科成績結(jié)果如下表所示:
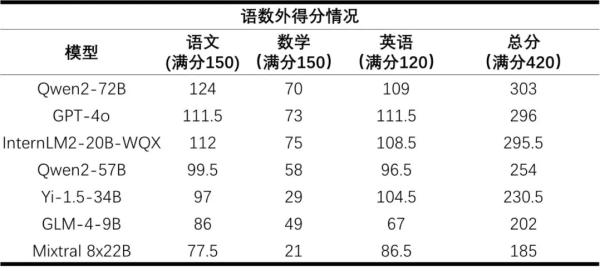
測評的大模型語數(shù)外得分情況 來源:上海市人工智能實(shí)驗室
總分前三名阿里巴巴開源的Qwen2系列MoE對話模型(Qwen2-72B)、GPT-4o及書生·浦語2.0文曲星(InternLM2-20B-WQX)對應(yīng)得分率分別為72.1%、70.5%和70.4%。大部分模型在“語言”本質(zhì)上的表現(xiàn)良好,語文平均得分為67分,英語更是達(dá)到了81分。
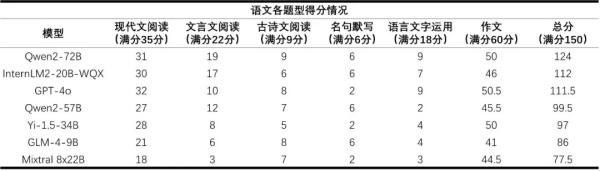
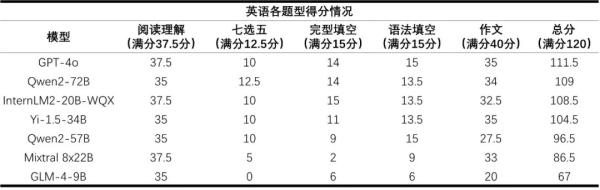
而數(shù)學(xué)則是所有大模型的短板,平均得分率僅為36%。得益于研究團(tuán)隊在數(shù)學(xué)推理上的投入,書生·浦語2.0文曲星(InternLM2-20B-WQX)取得了75分的最高分,超過所有受測模型。然而仍未達(dá)到及格水平,這表明大模型的數(shù)學(xué)能力存在較大提升空間。
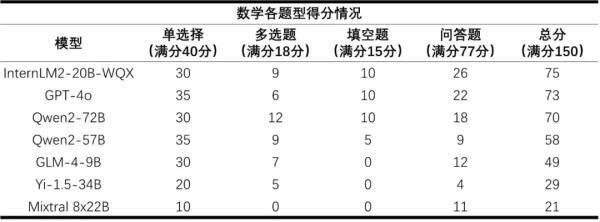
閱卷老師點(diǎn)評:大模型數(shù)學(xué)主觀題回答凌亂
參與評測的所有開源模型,權(quán)重均在2024年6月7日高考題目公布前開源,避免了“數(shù)據(jù)污染”和“刷題”風(fēng)險,與真實(shí)高考嚴(yán)格的“閉卷考試”一致,不存在“作弊”可能。
為貼近高考評卷模式,聯(lián)合團(tuán)隊邀請多位具有閱卷經(jīng)驗的高中教師對模型主觀題答案評分,每份考卷至少由3位教師分別打分。本次在完成所有大模型答卷的評卷工作后,研究人員同時邀請了各科教師對大模型表現(xiàn)進(jìn)行了整體分析,為模型能力提升策略提供參考。
閱卷教師認(rèn)為,在語文科目上,模型的現(xiàn)代文閱讀理解能力普遍較強(qiáng),但是不同模型的文言文閱讀理解能力差距較大。大模型作文更像問答題,雖然有針對性但缺乏修飾,幾乎不存在人類考生都會使用舉例論證、引用論證、名人名言和人物素材等手法。多數(shù)模型無法理解“本體”“喻體”“暗喻”等語文概念。語言中的一些“潛臺詞”,大模型尚無法完全理解。
在數(shù)學(xué)科目上,閱卷教師表示,大模型的主觀題回答相對凌亂,而且過程具有迷惑性,甚至出現(xiàn)了過程錯誤但得到正確答案的情況。此外,大模型的公式記憶能力較強(qiáng),但無法在解題過程中靈活引用。
相較于語文和數(shù)學(xué),閱卷教師認(rèn)為,在英語科目上大模型整體表現(xiàn)良好,但部分模型由于不適應(yīng)題型,在七選五、完形填空題等題型得分率較低。大模型英語作文普遍存在因超出字?jǐn)?shù)限制而扣分的情況,而人類考生多因為字?jǐn)?shù)不夠扣分。
聯(lián)合團(tuán)隊認(rèn)為,如同高考閱卷也存在細(xì)微差異,由于主觀題類型的引入,本次評測也無法做到絕對的公平。
司南評測體系OpenCompass于2023年7月由上海人工智能實(shí)驗室在世界人工智能大會上推出,目前升級為OpenCompass2.0,構(gòu)造了一套中英文雙語評測基準(zhǔn),涵蓋語言與理解、常識與邏輯推理、數(shù)學(xué)計算與應(yīng)用、多編程語言代碼能力、智能體、創(chuàng)作與對話等方面。




《中國城市報》社有限公司版權(quán)所有,未經(jīng)書面授權(quán)禁止使用
Copyright ? 2015-2025 by www.yktax-zh.com. all rights reserved












